
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 재귀
- Basic
- 기초
- Unity
- W3Schools
- python
- Class
- Algorithm
- Unreal Engine 5
- Material
- loop
- w3school
- DP
- 프로그래밍
- github
- C#
- 파이썬
- guide
- 문제풀이
- parameter
- UE5
- c++
- Programming
- String
- Tutorial
- dynamic
- 오류
- dfs
- 시작해요 언리얼 2022
- 백준
- Today
- Total
행복한 개구리
DB 복습 21.07.20. - MySQL 기초 ~ View, Foreignkey, Transaction, Procedure, Function, Trigger 본문
DB 복습 21.07.20. - MySQL 기초 ~ View, Foreignkey, Transaction, Procedure, Function, Trigger
HappyFrog 2021. 7. 17. 22:27MySQL Workbench를 사용할 것이다.
우선 MySQL에서 사용할 커넥션에 연결하여 스키마를 만들자.
스키마 이름은 마음대로 만들자.

- 스키마를 만들 때는 utf8과 utf8_bin으로 설정해주어야 영어가 아닌 언어도 정상출력된다.
그리고 테이블을 만들자.
나는 오늘 고객, 상품, 구매 기록테이블을 사용할것이다.
따라서 customer, products, hitstories라고 이름을 짓겠다.
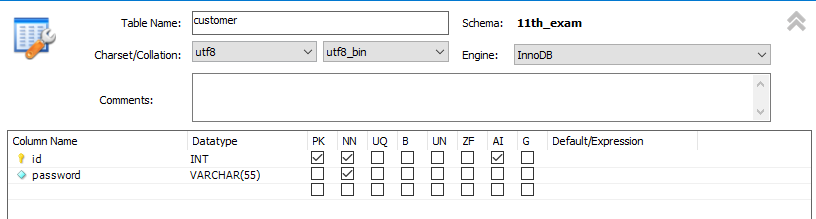


- Foreignkey를 사용할 것이라면 이어줄 키들의 데이터타입이 서로 일치해야한다. (글자 수 까지도)
CRUD
USE test;
SELECT * FROM customer;
INSERT INTO customer(id, password) VALUES (1, 123);
UPDATE customer SET password = 456 WHERE id = 1;
DELETE FROM customer WHERE id = 1;



- SELECT는 내가 선택한 테이블에서 선별적으로 데이터를 불러올 수 있다.
- 나는 * (=ALL)을 사용했기 때문에 테이블 전체를 다 가져온다.
- 모든 사진은 해당 코드 실행 후 SELECT하여 테이블은 확인한 결과이다.
- INSERT는 테이블에 데이터를 삽입(insert)하는 코드이다.
- 즉, 테이블에 새로운 데이터를 생성한다.
- UPDATE는 이미 존재하는 데이터를 수정한다.
- 위 사진에서는 비밀번호를 123에서 456으로 변경했다.
- DELETE는 뜻 그대로 지우는 코드다.
- 위 사진에서 보이듯이 DELETE한 후에는 테이블에 있던 데이터가 사라진다.
View(뷰)
참고한 블로그 : 뷰(View)란?
우선, View란?
내가 원하는 테이블들의 조합을 볼 수 있게해주는 것을 말한다.
ex) A테이블의 a요소와 B테이블의 b요소를 합쳐서 볼 수 있도록 해주기도 하며 단일 테이블의 원하는 요소들만 골라서 볼 수 있도록 해주기도 한다.
CREATE VIEW view_history
AS SELECT a.id, b.name, c.date
FROM customer AS a, products AS b, histories As c;
SELECT * FROM view_history;
- 위 코드를 적으면 해당 테이블의 칼럼들을 참조하여 데이터를 결합한 뷰를 생성할 수 있다.
- 뷰가 생성되면 Views에서 내가 만든 뷰를 볼 수 있는데, 생성이 되었다고 로그가 떴지만 Views에서 안보이면 Refresh를 해주자.




- 위 세가지가 합쳐져서 뷰가 된 모습이다.
- 원하는 데이터만 골라 볼 수 있어서 참 편하다.
- 내가 테이블을 결합시켜 만든 뷰는 실용성이 별로 없지만 그래도
Foreign Key(외래키)
외래키는 다른 테이블의 키를 해당 테이블에 할당하여 연동한 것이다.
주의할 점은 외래키를 할당할 때 할당할 칼럼은 반드시 키여야 한다.
그리고 외래키 부분에 연동된 키 값이 아닌 다른 값을 INSERT하려 하면 실행되지 않는다.

- Foreign Key는 위 사진에서 보이듯이 테이블에서 하단에 보이는 탭들 중 Foreign Keys탭에서 설정할 수 있다.

- 들어가면 이런 창이 나오는데 여기서 KeyName은 마음대로 설정하면 되고
- Referenced Table에서 원하는 테이블을 선택한다.
- 그리고 내가 할당해주고싶은 칼럼(Foreign Key를 설정하는 테이블의 칼럼)을 선택하고 다른테이블의 어떤 요소(Foreign Key로 쓰이는 테이블의 칼럼)를 할당할 것인지를 정한다.

- 이런식으로 설정할 수 있다.
- 해당 설정이 완료되면 위에서 서술했듯이 해당 칼럼에는 INSERT를 이용하여 Foreign Key와 다른 값을 할당할 수 없다.

- 조금 불편한 점이 있다면 부모테이블(외래키를 제공하는 테이블)의 내용이 추가된다고 해서 자식테이블(외래키를 할당받는/설정한 테이블)에 자동으로 데이터가 생성되지 않는다.
- 부모의 키중 어떤 것을 가져와야할 지 정해주지 않아서 그런듯 하다.
Transaction

- 트랜잭션을 사용하는 가장 큰 이유는 '고립성'때문이다.
- 고립성은 서로 다른 사용자가 DB를 이용할 때 트랜잭션을 이용하여 테이블에 대한 권한을 할당받았을 때, 권한을 할당받지 못한 사용자는 해당테이블의 내용을 변경할 수 없게 하는 것을 의미한다.
- 우선 트랜잭션을 사용하기위해서는 약간의 설정이 필요하다.
- AC(AUTO COMMIT)을 꺼주고, SAFE모드도 꺼주어야한다.
SELECT @@AUTOCOMMIT;- 해당 코드로 AUTO COMMIT 설정을 확인할 수 있는데, 1이면 켜져있는 것이고 0이면 꺼진것이다.

--끄기
SET AUTOCOMMIT = 0;
--켜기
SET AUTOCOMMIT = 1;- 위 코드로 AUTO COMMIT을 켜고 끌 수 있다.

- 그리고 Safe Updates는 Edit - Preferences의 SQL Editor에서 끌 수 있다.
- 해당 작업을 하는 이유는 오토커밋은 꺼야 트랜잭션을 사용할 수 있고
- Safe Updates를 꺼야 트랜잭션 상태에서 테이블 내용을 변경할 수 있다.
그리고 시간초과가 되어 Lock당한 모습을 봐야하니 cmd에서 mysql을 실행해준다.
그 다음엔 시간초과까지 걸리는 시간을 설정해주자(기본값이 50초여서 너무 길다.)
--timeout이 들어가는 값들을 보여줘.
SHOW VARIABLES LIKE "%timeout";
--lock 시간초과가 되는 시간을 보여줘.
SELECT @@innodb_lock_wait_timeout;


--전역으로 innodb_lock_wait_timeout 설정하기
SET GLOBAL innodb_lock_wait_timeout = (INT값)설정하고싶은시간;
--해당 세션에만 적용
SET SESSION innodb_lock_wait_timeout = 설정하고 싶은 시간;- 글로벌로 바꾸면 세션에 재접속해야 바뀐값이 보인다.
- 하지만 세션으로 바꾸면 재접속을 안해도 확인할 수 있다.
- => 트랜잭션 락을 확인하며 알았는데 세션에 적용하니까 변경이 안된채로 cmd에서 50초 기다렸다. - 글로벌로 바꾸자.
자, 이제 준비는 끝났으니 시작해보자.
--트랜잭션 시작
START TRANSACTION;
--커밋 => 트랜잭션을 실행중인 사용자가 변경한 내용을 세션에 적용하기 위함.
COMMIT;
--커밋한 것을 되돌릴 수 있음
ROLLBACK;- 트랜잭션 실행은 위 기능이 핵심적이다.
- 실행시키고, 적용하고, 필요하다면 되돌리는 기능이다.
- RollBack기능은 편리한 기능이라고 생각한다.
- Commit을 하지 않는다면 트랜잭션중에 데이터를 바꿔도 세션에 적용되지 않는다.

- 홍길서의 비밀번호를 보면 트랜잭션이 실행중인(권한이 있는)테이블에서는 789로 변경이 되었고 권한이 없는 테이블은 이전 데이터가 그대로 남아있다.
- 그리고 이어서 cmd에서 해당 데이터테이블을 수정해보자.

- 변경이 되지않고 대기시간이 길어지며 해당 lock_time_out시간이 지나면 다음과 같은 에러가 난다.
- 이것이 바로 트랜잭션의 고립성이다.
- 권한을 가진 사용자 외에는 DB를 수정할 수 없다.

- 그리고 COMMIT을 하면 바로 다른 사용자에게도 데이터가 수정된 채로 출력된다.
- 그리고 ROLLBACK은 COMMIT 되고 나면 할 수 없다.
- 또한 DROP시킨 테이블, 스키마 등 드랍시킨 것들은 ROLLBACK이 안되며, 테이블의 구성을 바꾸는 AlterTable 작업 또한 ROLLBACK이 불가능하다.
PROCEDURE
DB에서는 Stored Procedure를 사용가능한데, 이는 쿼리들을 하나의 함수처럼 사용하기 위한 집합이다. => 저장되는 함수라고 생각하면 편하다.
프로시저를 만드는 방법은 두가지가 있다.
- 워크벤치에서 인터페이스를 이용하여 만드는 방법과
- 쿼리코드로 작성하여 만드는 방법이 있다.
1. 인터페이스 활용


- Stored Procedures - 우클릭 - Create Stored Procedure... 을 클릭하면 위와 같은 창이 나오는데,
- new_procedure부분에 프로시저 이름을 적어주고
- BEGIN과 END사이에 프로시저 내용을 적어주면 된다.
2. 코드로 생성
DELIMITER // --구분선 같은 느낌
--CREATE 함수를 이용하여 PROCEDURE 생성. 메서드 이름같은게 프로시저 이름이 됨.
CREATE PROCEDURE find_products(products_id INT)
--BEGIN과 END 사이에 내용선언
BEGIN
--변수선언
DECLARE count INT;
--COUNT함수를 사용하여 매개변수보다 큰 id값을 가진 상품들의 갯수를 구함. => 출력 x
SELECT COUNT(*)
INTO count
FROM products
WHERE id > products_id;
--결과값이 존재한다면 해당 항목의 정보를 선별적으로 불러옴
IF count > 0
THEN SELECT name, category, price
FROM products
WHERE id >= products_id;
--조건문 끝
END IF ;
--프로시저 내용 끝
END //
DELIMITER ; --구분선 같은 느낌

- CREATEPROCEDURE로 프로시저를 생성해준다. C#에서 메서드 이름같이 보이는것이 프로시저의 이름이 된다.
- 그리고 BEGIN과 END사이에 내용을 선언해주면 된다.
- 내용으로는 원하는 ID값 범위에 있는 데이터들의 정보를 가져오도록 설정했다.
- 쿼리에서는 조건문을 끝낼 때 ENDIF를 사용하여 조건문이 끝났음을 선언해야 한다.
- 그리고 Function이나 Procedure생성 등 메서드같은 것을 선언할 때 DELIMITER를 사용하여 구분지어 주어야 한다. => 가독성도 가독성이지만 안하면 오류난다.
--CALL "프로시저 이름"(매개변수)
CALL find_products(8100);- 프로시저 실행은 위와 같이 CALL을 사용한다.


- 8100보다 큰 id를 가진 항목들만 출력됐다.
Function
말 그대로 함수다.
쿼리에서도 우리가 원하는 대로 함수를 만들어 사용할 수 있다.
- 다만 프로시저와 다른 점은 반환타입이 존재한다는 것이다.
- 이 말인 즉, 테이블을 반환받고 싶다면 프로시저를 이용해야 한다.
이번엔 histories에서 지금으로부터 n분 전의 데이터를 가져와보자.
--SELECT * FROM histories WHERE date > (NOW() - INTERVAL {원하는 숫자} {원하는 시간 단위});
--초 = SECOND
--분 = MINUTE
--시간 = HOUR
--일 = DAY
--달 = MONTH
--년 = YEAR
SELECT * FROM histories WHERE date > (NOW() - INTERVAL 75 MINUTE);- 지금으로부터 75분전의 데이터를 가져오는 함수이다.
- 조금 더 가공해서 만든 함수에서 사용해보자
DELIMITER //
CREATE FUNCTION recent_customers_count(past_time INT) returns INT
BEGIN
DECLARE count INT;
SELECT COUNT(*)
INTO count
FROM histories
WHERE date > (NOW() - INTERVAL past_time MINUTE);
return count;
END //
DELIMITER ;- 프로시저와 구성이 비슷하므로 주석은 달지 않았다.
- 하지만 다른점이 있다면, 함수를 선언하면서 바로 returns를 통해 반환타입을 지정한다.
- 그리고 마지막에 반환타입과 일치하는 값을 반환해준다.
SELECT recent_customers_count(90);- 함수는 SELECT함수를 사용하여 실행한다.

Error Code: 1418. This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
SET GLOBAL log_bin_trust_function_creators = 1;
- 만약 해당 에러가 난다면 에러 아래에 적어둔 코드를 실행시켜 function생성에 대한 권한을 설정하고 함수를 다시 실행시켜보자.



- 실행결과는 다음과 같이 나왔다.
- 매개변수의 값에 따라 출력되는 값이 다르다.
TRIGGER
트리거는 어떠한 쿼리가 실행된 전/후에 반응하여(On Trigger) 실행시키는 쿼리를 말한다.
나는 비슷한 느낌으로 C#의 콜백메서드를 생각했다.

- Trigger에서는 사용할 수 있는 칼럼이 제한된다.
- 제한상황은 위 표에 나와있으니 참고하자.
DELIMITER //
CREATE TRIGGER log_customers_join_date
AFTER INSERT ON customer FOR EACH ROW
BEGIN
INSERT INTO log_customer_join_date(customer_id) VALUES (new.id);
END //
DELIMITER ;- 역시나 Function, Procedure과 비슷한 형식이다.
- 하지만 다른점은 매개변수를 아예 선언조차 하지 않는다는 것이고
- AFTER(BEFORE) INSERT(DELETE/UPDATE) ON 이라는 함수를 사용한다는 것과
- INSERT를 할 때 new(old)를 사용한다는 점이다.

SHOW TRIGGERS;- 해당 코드를 실행하면 트리거 생성에 대한 로그가 나온다.

DROP TRIGGER IF EXISTS Trigger명;- 만약 트리거를 재 등록하고 싶다면 트리거를 연결해둔 테이블의 Triggers탭으로가서 트리거를 해제하거나
- 위 코드를 실행해주자.
INSERT INTO customer(id, name, password)
VALUES (7, "끝이당", 8282);
SELECT * FROM customer;
SELECT * FROM log_customer_join_date;- 해당 코드로 INSERT하며 트리거를 발동시키고 트리거가 입력해주는 테이블의 결과를 보자.


- 위와 같이 customer 테이블에 데이터를 INSERT 한 후에 자동으로 log_customer_join_date 테이블에 데이터가 할당되는 것을 확인할 수 있다.
하다보니 너무 늦었다.
이거저거 오류 해결하면서 쭉 복습하다보니 4~5시간정도 걸린듯 하다.
뭐 언제나 그랬듯이 익숙해지면 빨라지겠지.
지금 무엇보다도 해결이 안되는 문제는 SQL 매뉴얼이나 API를 어디서 찾아야 할 지 잘 모르겠다는 점이다.
쨋든 이제 쉬어야징